Salida de la estimación MCO del modelo
- En la columna sombreada figuran los valores de los estimadores MCO correspondientes a los coeficientes \beta_i del modelo.
- «Std. Error» son las desviaciones típicas estimadas de los estimadores: S_{b_i} = \sqrt{S^{2} · x^{ii}}
- S.E.of regression —Error estándar de la regresión— es la raíz cuadrada de S^{2}
- Sum squared resid es la suma de cuadrados de errores (SCE)
- Mean dependent var es la media de los valores de la variable explicada —ventas— en la muestra.
- S.D. dependent var es la cuasi-desviación típica muestral del regresando:
S.D. \thinspace dependent \thinspace var = \sqrt{\frac{\sum (y_{t} – \overline y)^{2}}{T – 1}} =\sqrt{\frac{SCT}{T – 1}}= \sqrt{\frac{Y´Y – T · \overline {y}^{2}}{T – 1}}
Salida de la matriz de varianzas-covarianzas estimada de los estimadores
 Los valores resaltados — elementos diagonales — son las varianzas estimadas de los estimadores ( S^{2}_{b_{i}}=S^{2} · x^{ii})
Los valores resaltados — elementos diagonales — son las varianzas estimadas de los estimadores ( S^{2}_{b_{i}}=S^{2} · x^{ii})
Los elementos no diagonales son las covarianzas estimadas de los estimadores ( S_{b_{i}b_{j}}=S^{2} · x^{ij} ).
Salida de la tabla de valores observados —‘Actual‘— y estimados —‘Fitted’— del regresando y de los errores de estimación —‘Residual’—
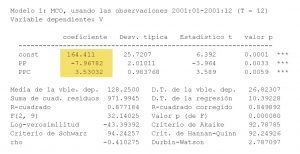
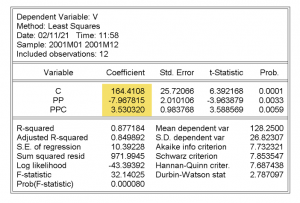
Salida de la estimación MCO del modelo
- En la columna sombreada figuran los valores de los estimadores MCO correspondientes a los coeficientes \beta_i del modelo.
- «Desv. típica» son las desviaciones típicas estimadas de los estimadores: S_{b_i} = \sqrt{S^{2} · x^{ii}}
- D.T. de la regresión —Error estándar de la regresión— es la raíz cuadrada de S^{2}
- Suma de cuad. residuos es la suma de cuadrados de errores (SCE)
- Media de la vble. dep. es la media de los valores de la variable explicada —ventas— en la muestra.
- D.T. de la vble. dep. es la cuasi-desviación típica muestral del regresando:
D. T \thinspace de\thinspace la \thinspace vble. \thinspace dep. = \sqrt{\frac{\sum (y_{t} – \overline y)^{2}}{T – 1}} =\sqrt{\frac{SCT}{T – 1}}= \sqrt{\frac{Y´Y – T · \overline {y}^{2}}{T – 1}}
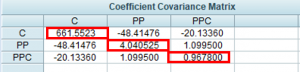
Salida de la matriz de varianzas-covarianzas estimada de los estimadores

Los valores resaltados — elementos diagonales — son las varianzas estimadas de los estimadores ( S^{2}_{b_{i}}=S^{2} · x^{ii})
Los elementos no diagonales son las covarianzas estimadas de los estimadores ( S_{b_{i}b_{j}}=S^{2} · x^{ij} ).
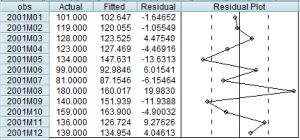
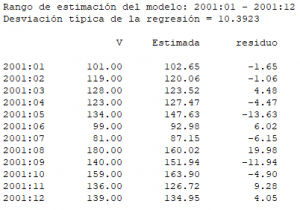
Salida de la tabla de valores observados —‘V‘— y estimados —‘Estimada’— del regresando y de los errores de estimación —‘residuo’—
Salida de la estimación MCO del modelo
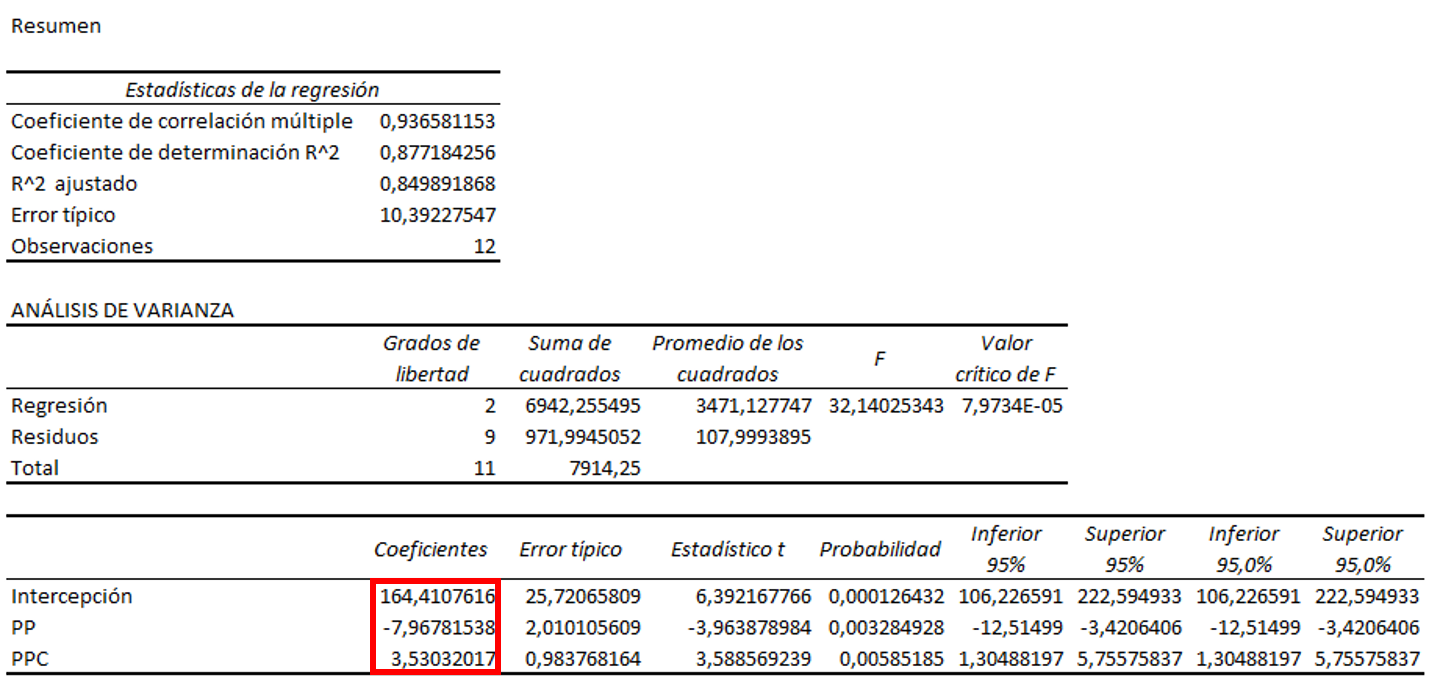
Tabla ‘Resumen’
- Error típico —Error estándar de la regresión— es la raíz cuadrada de S^{2}
Tabla ‘Análisis de la varianza’— columna ‘Suma de cuadrados’
- Total es la suma de cuadrados de totales
SCT = \sum (y_{t} – \overline {y})^{2} =\sum y_{t}^{2}- T \overline {y}^{2} = Y^{\prime}Y – T \overline {y}^{2} - Residuos es la suma de cuadrados de errores (SCE)
- Total es la suma de cuadrados de totales
Última tabla
- En la columna sombreada figuran los valores de los estimadores MCO correspondientes a los coeficientes \beta_i del modelo.
- En la columna «Error típico» figuran las desviaciones típicas estimadas de los estimadores: S_{b_i} = \sqrt{S^{2} · x^{ii}}
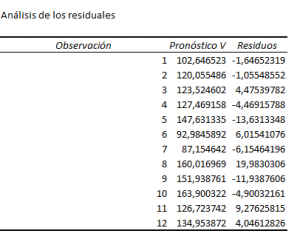
Salida de la tabla de valores estimados del regresando—‘Pronóstico V’— y de los errores de estimación —‘Residuos’—