El propietario de una red de gasolineras repartidas por todo el territorio nacional está considerando la posibilidad de redimensionar su empresa pero, antes de tomar una decisión, quiere saber cuáles son las previsiones que hay en relación al consumo de gasolina en España. Se pone en contacto con una investigadora que ha especificado y estimado un modelo que relaciona el consumo de gasolina para automoción en España (CGA, expresado en miles de toneladas métricas), con el índice de precios al consumo (IPC, base 2011 = 100) y con un índice de renta salarial (IRS, base 2011 = 100).
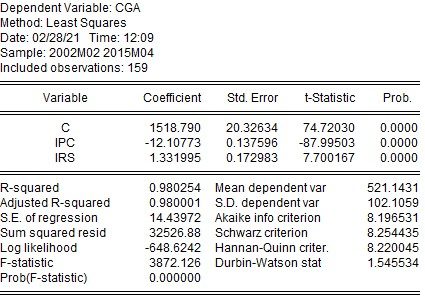
Para estimar el modelo se han utilizado datos mensuales del período comprendido entre febrero del 2002 y abril del 2015. La función de regresión estimada se adapta bien a los datos (R^2 = 0.98 y %RECM = 2,74%), las estimaciones de los parámetros son coherentes con los supuestos teóricos, ya que indican la existencia de una relación directa entre el consumo de gasolina y la renta e inversa entre entre los precios y el consumo de este combustible y las dos variables explicativas son relevantes prácticamente a cualquier nivel de significación.
Pero para responder a la cuestión planteada por el empresario, la investigadora ha de comprobar si esta relación estimada es válida para efectuar predicciones porque para que el pronóstico sea fiable, además, es necesario que la relación existente entre las variables sea estable, es decir, que los parámetros \beta_i tomen los mismos valores en el período muestral y en el de predicción.
Finalmente, antes de aventurarse a efectuar pronósticos, ha de valorarse la capacidad predictiva del modelo y con este objetivo se han reservado las observaciones correspondientes al período comprendido entre mayo del 2015 y diciembre de este mismo año que se emplearán para comparar los valores reales que tomó la variable ‘Consumo de gasolina para automoción’ con los que el modelo prevé.

Con los datos de las variables ‘Consumo de gasolina para automoción‘, ‘Índice de precios al consumo’ e ‘Índice de renta salarial‘ para el período comprendido entre mayo y diciembre de 2015, se calcula los valores previstos para la variable explicada.
\begin{array}{c} \widehat {CGA}_{20015M05} = 1518,79 -12,10773 \times 104,109 +1,331995 \times 97,49040 = 388,483\\ ·························\\ \widehat {CGA}_{20015M12} = 1518,79 -12,10773 \times 103,490 +1,331995 \times 97,98135 = 396,271\end{array}
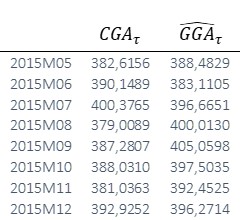
Los resultados obtenidos para todo el período de predicción se recogen en la siguiente tabla
Cálculo del intervalo de confianza del 95% para el valor puntual de la variable ‘Consumo de gasolina para automoción’ en el primer período de predicción: mayo de 2015.
( \widehat {CGA}_{\tau} – S_{e_{\tau}}t^{\alpha/2}_{T-k-1}; \widehat {CGA}_{\tau} + S_{e_{\tau}}t^{\alpha/2}_{T-k-1})

S_{e_{2015M05}} = \sqrt{S^2+ X^{\prime}_{2015M05} \widehat {V}(b)X_{2015M05}} = 14,56
S^2= \frac{32526,88}{159-2-1}=208,51
X^{\prime}_{2015M05} \widehat {V}(b)X_{2015M05} = \begin{pmatrix} 1 & 104,11 & 97,49 \end{pmatrix}\begin{pmatrix} 413,1599 & -1,5318 & -2,7289 \\ -1,5318 & 0,0189 & -0,0024 \\ -2,7289 & -0,0024 & 0,0299 \end{pmatrix} \begin{pmatrix} 1 \\ 104,11 \\ 97,49\end{pmatrix} = 3,61
t^{0,025}_{156}=1,97
(388,48 – 14,56 \times 1,97; 388,48 + 14,56 \times 1,97) = (359,7145;417,2513)
Intervalos de confianza del 95% para los valores puntuales de la variable ‘Consumo de gasolina para automoción’ para todos los períodos de predicción.

Estadístico F de Chow y Fisher
- Período de estimación: febrero 2002 —abril 2015 ( T=159 )
- Período de predicción: mayo 2015 — diciembre 2015 ( n=8 )

H_0: \beta_{i \tau} = \beta_i \: \forall i= 0,1, 2 \: \forall \tau = 1,2, ···,8
H_1: \beta_{i \tau} \neq\beta_i \: \forall i= 0,1, 2 \: \forall \tau = 1,2, ···,8
Valor del estadístico en la muestra:
F =\large \frac{(33567,14 – 32526,88)/8}{32526,88/(159-2-1)} \normalsize {= 0,6236}
Regla de decisión e interpretación:
F = 0,6236 < F^{0,05}_{(8,156)} = 1,9982 \rightarrow NRH_{0}
Al nivel de significación del 5%, no hay evidencia en contra de la estabilidad paramétrica. El modelo se considera apropiado para predecir.
Con EViews
Para hacer el contraste de estabilidad paramétrica, se estima el modelo para las 167 observaciones —T = 159 + n = 8— y en la cinta de opciones «View» se selecciona «Stability Diagnostics — Chow Forecast Test» . A continuación, se indica el primer período de predicción: mayo de 2015.

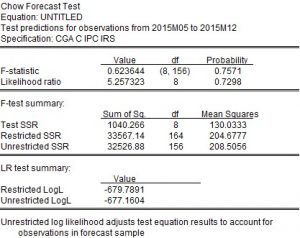
Regla de decisión e interpretación:
La probabilidad asociada al estadístico F (0,7571) es muy alta. A los niveles de significación habituales, la hipótesis de estabilidad paramétrica no se rechaza.
El modelo se considera apropiado para predecir.
Estadístico t_\tau
Contraste de estabilidad de los parámetros para el primer período de predicción: mayo de 2015
H_0: \beta_{i 2015M05} = \beta_i \thinspace \forall i= 0,1, 2
H_1: \beta_{i2015M05} \neq \beta_i \thinspace \forall i= 0,1, 2
Para obtener el valor del estadístico en la muestra, ha de calcularse el error de predicción y el de su desviación típica estimada para esta observación.
e_{2015M05} = CGA_{2015M05} – \widehat {CGA}_{2015M05} = 382,6156 – 388,4829 = -5,8673
S_{e_{2015M05}} = \sqrt{S^2+ X^{\prime}_{2015M05} \widehat {V}(b)X_{2015M05}} = 14,56
t_{2015M05} = \frac{-5,8673}{14,56}=-0,40
Regla de decisión e interpretación:
|t_{2015M05} |=0,40< t^{0,025}_{156} = 1,97 \rightarrow NRH_{0}
En mayo de 2015, al nivel de significación del 5%, no hay evidencia en contra de la hipótesis de estabilidad paramétrica.
Contraste para los restantes períodos de predicción
Valores de los estadísticos de prueba en la muestra:

Regla de decisión e interpretación:
En todos los casos:
|t_{\tau} | < t^{0,025}_{156} = 1,97 \rightarrow NRH_{0}
Para todos los períodos, al nivel de significación del 5%, la muestra no contradice la hipótesis de estabilidad paramétrica. El modelo puede utilizarse para predecir el consumo de gasolina para automoción en todos los periodos de predicción.
EViews y Gretl no calculan los valores de los estadísticos t para cada período de predicción pero sí proporcionan los previstos para la variable explicada y los de las desviaciones típicas estimadas de los errores de predicción.
Para obtener estos valores con Gretl, se estima el modelo para las observaciones muestrales —T = 159— y en la cinta de opciones «Análisis» se selecciona «Predicciones».
A continuación, ha de señalarse el período de predicción — de mayo a diciembre de 2015— y el nivel de confianza.
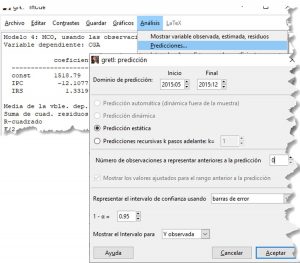

Una vez estimado el modelo con las T observaciones muestrales, se selecciona en el menú «Procs» la opción «Forecast«

En la parte izquierda de la salida de la predicción se representa gráficamente la serie de las predicciones de la variable ‘Consumo de gasolina para automoción‘ (CGAF) —línea continua— y los límites inferior y superior de los intervalos de confianza para las predicciones —líneas discontinuas— al nivel de confianza del 95% para el período de predicción —Forecast Sample—.
En el lado derecho, EViews proporciona información sobre diferentes medidas evaluadoras de la capacidad predictiva que calcula de forma automática:
- Los valores de las dos primeras, Raíz del Error Cuadrático Medio de la predicción —Root Mean Squared Error— y Error Absoluto Medio de la predicción —Mean absolute Error— dependen de las unidades de medida del regresando por lo que no es posible determinar un valor de referencia para valorar la calidad de las predicciones. Cuanto menor es su valor, mejor predice el modelo.
- El Porcentaje del Error Absoluto de la predicción —Mean Abs. Percent Error (MAPE)— mide el error en términos porcentuales, es adimensional. Toma valores entre cero e infinito y, en la práctica, habitualmente, se considera una buena capacidad predictiva cuando es inferior al 5%.
Dado que la distribución de los porcentajes de valores absolutos es frecuentemente asimétrica con sesgo a la derecha, EViews también calcula el Porcentaje del Error Absoluto medio simétrico —Symmetric MAPE—
sMAPE =(\frac{1}{n} \sum_{\tau=1}^{n} \frac{\lvert y_{\tau} – \widehat {y}_{\tau} \lvert}{(y_{\tau}+\widehat{y}_{\tau})/2 })\times 100 - Finalmente, se muestran los valores de dos medidas propuestas por Theil. El primero —Theil Inequality Coef.— es una medida de exactitud, mientras que el segundo —Theil U2 Coefficient— es una medida de la calidad del pronóstico.
Theil Inequality Coef. toma valores entre cero y uno. Cuanto más se aproxime a uno, peor es el pronóstico. Para establecer el origen de la desigualdad entre los valores reales y previstos del regresando, EViews también proporciona la descomposición del error cuadrático medio en las proporciones del sesgo —Bias Proportion—, de la varianza —Variance Proportion— y de la covarianza — Covariance Proportion—. La suma de las tres es igual a la unidad y cada una de ellas varía entre cero y uno. Si el modelo predice bien, las proporciones del sesgo y de la varianza están próximas a cero y la de la covarianza a uno.
El estadístico U2 de Theil permite comparar la calidad del pronóstico realizado con el modelo propuesto con la correspondiente a un modelo ingenuo o «naive» —por ejemplo \widehat {y}_{\tau} = y_{\tau-1}—. U2 toma valores entre cero e infinito. Si el modelo propuesto predice mejor que el ingenuo, U2 toma un valor menor que 1. Cuando toma el valor 1 es indicativo de que la calidad del pronóstico es idéntica en ambos modelos.
Una vez estimado el modelo con las T observaciones muestrales, se selecciona en el menú «Análisis» la opción «Predicciones«

A diferencia de EViews, Gretl proporciona el valor del Error Medio de la predicción que no sirve para valorar el tamaño de los errores.