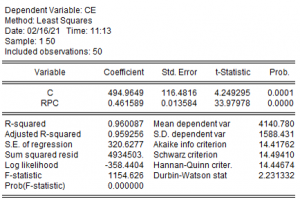
Para medir el efecto de la renta per cápita (expresada en miles de euros) sobre el consumo de energía (expresado en kilovatios/hora), se han recogido datos para 50 individuos y se ha estimado por MCO el modelo que relaciona a ambas variables.
¿Podría decirse que las observaciones están muy agrupadas alrededor de la recta de regresión estimada o, por el contrario, están muy dispersas? ¿Qué parte de la variación del consumo de energía explica la regresión?¿la renta per cápita explica bien el consumo de energía?
Para responder a estas preguntas, podríamos representar gráficamente la nube de puntos y valorar, intuitivamente, si la recta de regresión estimada se ajusta bien a los datos.
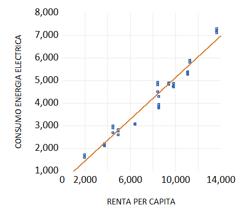
Pero, ¿estamos seguros de nuestro criterio? ¿cómo lo hacemos si el modelo es múltiple (más de una variable explicativa) teniendo en cuenta que, en este caso, la función de regresión estimada es un hiperplano?
Lo más útil es disponer de medidas que resuman esta información y nos permitan evaluar la calidad del ajuste efectuado.
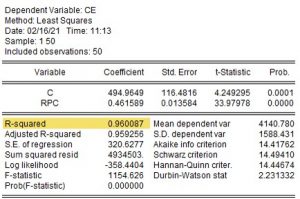
El valor del coeficiente de determinación está próximo a uno, por lo que puede decirse que, según esta medida, el ajuste es bueno. El modelo explica, aproximadamente, el 96% de las variaciones muestrales del consumo de energía (R^2 \times 100 \approx 0,96% ).
RECM = \widehat \sigma = \sqrt \frac{4934503}{50} = 314,15
%RECM = \frac{314,15}{4140.78} \times 100 = 7,59%
Por término medio, el porcentaje de error que se comete al estimar los valores del consumo de energía utilizando este modelo es del 7,59%. Según esta medida, el ajuste no es bueno.
En este caso, no es posible evaluar la calidad del ajuste con estas medidas.
En la ecuación del modelo que explica el comportamiento del consumo de energía, se incorpora, como variable explicativa el precio de la energía (PE), expresada en euros por kilovatio hora.
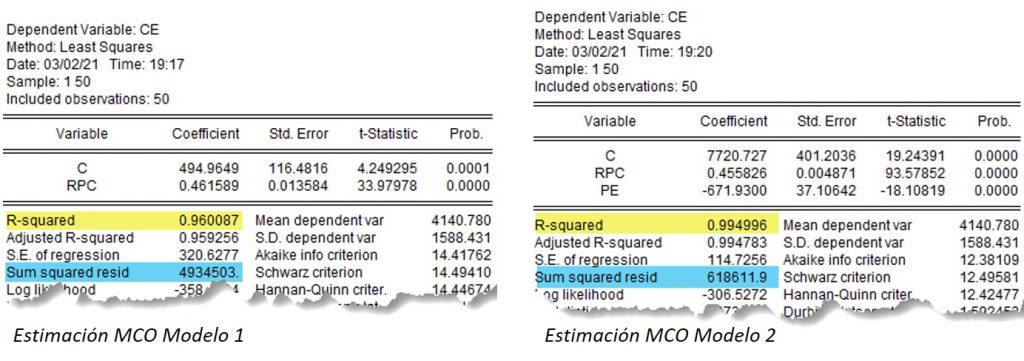
Al aumentar k —número de variables explicativas— la suma de cuadrados de errores disminuye:
\bigtriangledown {SCE} = 4.934.503 – 618.611,9 = 4.315.891,1
y se pierde un grado de libertad. Como la suma de cuadrados de totales no cambia, ya que en ambos casos se utiliza la misma muestra y la variable explicada es la misma, el valor de R^2 aumenta. Esto no quiere decir que el ajuste mejore.
En este caso, el valor de \overline {R}^2 en el primer modelo es inferior al del segundo, por tanto es mejor la calidad del ajuste del modelo 2.